The Hitchhiker's Guide to Concurrency
Nằm xa trong vũng nước đọng chưa ai thám hiểm của thế kỷ 21 có một lượng nhỏ tri thức. Far out in the uncharted backwaters of the unfashionable beginning of the 21st century lies a small subset of human knowledge.
cùng với tập con tri thức là một sự rèn luyện nhỏ bé không có nghĩa lí gì mà ở đó kiến trức Von Neumann-descended ngạc nhiên khi vẫn nghĩ ràng máy tính RPN là một ý tưởng gọn gàng. Within this subset of human knowledge is an utterly insignificant little discipline whose Von Neumann-descended architecture is so amazingly primitive that it is still thought that RPN calculators are a pretty neat idea.
sự rèn luyện này có , nói chính xác hơn là đã có một vấn đề đó là hầu hết những người học nó đều cảm thấy không vui vẻ gì, họ mất quá nhiều thời gian đối với việc viết một phần mềm song song. Rất nhiều giải pháp đã được đặt ra, nhưng hầu hết trong số chúng đều liên quan nhiều tới việc xử lí các đoạn logic nhỏ được gọi là locks và mutexes. Việc làm này thật thừa thãi vì những đoạn logic đó hầu hết không cần cho việc xử lí song song`. This discipline has — or rather had — a problem, which was this: most of the people studying it were unhappy for pretty much of the time when trying to write parallel software. Many solutions were suggested for this problem, but most of these were largely concerned with the handling of little pieces of logic called locks and mutexes and whatnot, which is odd because on the whole it wasn't the small pieces of logic that needed parallelism.
Vì thế vấn đề này vẫn còn tồn động, chưa được giải quyết, rất nhiều người khó chịu và đã số họ khổ sở , thậm chi là cả RPN calculators. nhưng rồi hầu hét trong số họ cũng đều And so the problem remained; lots of people were mean, and most of them were miserable, even those with RPN calculators.
Càng ngày càng có nhiều người cho rằng họ đã sai khi cố gắng thêm tính song song vào ngôn ngữ lập trình của họ và họ cho rằng không có chương trình nào có thể rời khỏi thread ban đầu cả. Many were increasingly of the opinion that they'd all made a big mistake in trying to add parallelism to their programming languages, and that no program should have ever left its initial thread.
Lưu ý:Đoạn này được viết như là một parody của The Hitchhiker's Guide to the Galaxy. Hãy đọc nó nếu bạn chưa đọc. Nó rât tuyệt! Read the book if you haven't already. It's good!
Don't Panic
Xin chào, Ngày hôm nay ( hay chính xác là bắt đầu từ bây giờ ), tối sẽ bắt đầu nói với bạn về concurrent trong Erlang.
Có thể bạn đã từng tìm hiểu và làm việc với concurrency trước đó.  Có lẽ bạn cũng quan tâm tới sự xuất hiện của các chương trinh đa lõi ( multi-core ).
Dù sao đi liệu thì bạn đang đọc cuốn sách này và tất cả những điều đang nói ở đây sẽ là về concurrency.
Today (or whatever day you are reading this, even tomorrow), I'm going to tell you about concurrent Erlang.
Chances are you've read about or dealt with concurrency before.
You might also be curious about the emergence of multi-core programming.
Anyway, the probabilities are high that you're reading this book because of all this talk about concurrency going on these days.
Có lẽ bạn cũng quan tâm tới sự xuất hiện của các chương trinh đa lõi ( multi-core ).
Dù sao đi liệu thì bạn đang đọc cuốn sách này và tất cả những điều đang nói ở đây sẽ là về concurrency.
Today (or whatever day you are reading this, even tomorrow), I'm going to tell you about concurrent Erlang.
Chances are you've read about or dealt with concurrency before.
You might also be curious about the emergence of multi-core programming.
Anyway, the probabilities are high that you're reading this book because of all this talk about concurrency going on these days.
Tuy nhiện, tôi có một lời cảnh báo với bạn trước khi đọc chương này, chương này sẽ chủ yếu nặng vê lý thuyết do đó nếu bạn đang stress, đâu đâu hoặc không thích tìm hiểu đối lịch sử của ngôn ngữ lập trình và chủ yếu chủ muốn lập trình thôi thì bạn có thể bỏ qua và đi thẳng tới cuối chương để sang chương sau này nơi mà có lẽ bạn sẽ tìm thấy nhiều ví dụ luyện tạp hơn. A warning though; this chapter is mostly theoric. If you have a headache, a distaste for programming language history or just want to program, you might be better off skipping to the end of the chapter or skip to the next one (where more practical knowledge is shown.)
Như tôi đã nói trước nói trong phần giới thiẹu cuốn sách, bản chất concurrency trong Erlang là truyền thông điệp ( message passing ) qua lại giữa các actor model, và tôi cũng lấy một ví dụ minh họa thông qua việc con người giao tiếp qua lại với nhau thông qua những bức thư. Một lát nữa tôi sẽ giải thích chi tiết hơn, còn giờ có một đièu rất quan trọng mà tôi tin rằng bạn cần phải hiểu đó là khái niệm và sự khác nhau giữa concurrency và parallelism.
Có thể bạn đã từng tìm hiểu thông qua một số sách hay hướng dẫn, và có thể rất nhiều trong số chúng đều hướng tới sự tương đồng về khái niệm của hai tính chất này. Tuy nhiên trong Erlang chúng hoàn toàn là hai khái niệm khác nhau. Với những người lập trình Erlang, concurrency hướng tới một ý tưởng về số lượng các actor chạy độc lập với nhau, và không bắt buộc tất cả chúng phải chạy trong cùng một thời điểm. Trong khí đó Parallelism thì lại hướng tới việc các actor chạy song song cùng trong một thời điểm cụ thể. Tại sao có sự khác nhạu, một phần là bởi không có một sự đồng thuận nào rõ ràng về các đinh nghĩa trong các lính vực khác nhau của khoa học máy tính. Do đó bạn không cần phải ngạc nhiên nếu trong một số tài liệu, nguồn khác một số người sử dụng các thuật ngữ này với nghĩa khác nhau và trong cuốn sách này tôi sẽ chỉ sử dụng khái niệm mà tôi vừa nêu ra. In many places both words refer to the same concept. They are often used as two different ideas in the context of Erlang. For many Erlangers, concurrency refers to the idea of having many actrs running independently, but not necessarily all at the same time. Parallelism is having actors running exactly at the same time. I will say that there doesn't seem to be any consensus on such definitions around various areas of computer science, but I will use them in this manner in this text. Don't be surprised if other sources or people use the same terms to mean different things.
Có thể nói chính xác răng ngày từ lúc bắt đầu xây dưng Erlang, nó đã hỗ trợ concurrency rồi, thậm chí ngay cả từ những thập niên ́80's khi mà máy tính chỉ phổ biến với lõi đơn . mỗi tiến trình trong Erlang đều có từng khỏng thời gian riền để chạy, tương tự như những gì mà các ứng dụng desktop đã làm trước đó với hệ thống đa lõi. This is to say Erlang had concurrency from the beginning, even when everything was done on a single core processor in the '80s. Each Erlang process would have its own slice of time to run, much like desktop applications did before multi-core systems.
tại thời điểm đó parallelism vẫn có thể được thực hiện; nhưng để làm dược điều này bạn sẽ cần thêm một máy tính khác để giao tiếp cùng máy tính hiện tại. Dù vậy , với Erlang bạn vẫn có thể thực hiện chạy song song chỉ với hai actor trên một máy. Ngày nay, các hệ thống đa lõi đều cho phép bạn chạy song song trên cùng một máy tính ( một số cpu của máy tính còn có thể chứa hàng chục lỗi ) và điều này giúp Erlang có thể tận dụng tối đã được khả năng này. các cpu của máy tính hầu hết đều hỗ trợ đa lõi do đó cács cho phép bạn chạy song song trên một máy tính all you needed to do was to have a second computer running the code and communicating with the first one. Even then, only two actors could be run in parallel in this setup. Nowadays, multi-core systems allows for parallelism on a single computer (with some industrial chips having many dozens of cores) and Erlang takes full advantage of this possibility.
Don't drink too much Kool-Aid:
Điều quan trọng là phải hiểu được sự khác nhau giữa concurrency và parallelism,
Nhiều lập trình viên tin rằng Erlang đã hỗ trợ sẵn trên các máy tính đa lõi tù trước nhưng thực tế là giữa những năm 2000 khi đó Erlang mới chỉ áp dụng
symmetric multiprocessing, phải tới năm 2009 sau khi bản R13B
được phát hành nó mới hỗ trợ hoàn chỉnh. Một điều nữa là trước đó tính năng SMP
trong Erlang thường bị vô hiệu hóa để tránh ảnh hưởng tới hiệu suất. Trong trường hợp máy tính của bạn không hỗ trợ SMP,
bạn có thể thực hiện nó bằng cách chạy nhiều máy ảo cùng lúc.
The distinction between concurrency and parallelism is important to make,
because many programmers hold the belief that Erlang was ready for multi-core computers years before it actually was.
Erlang was only adapted to true symmetric multiprocessing
in the mid 2000s and only got most of the implementation right with the R13B release of the language in 2009.
Before that, SMP often had to be disabled to avoid performance losses.
To get parallelism on a multicore computer without SMP, you'd start many instances of the VM instead.
Một đièu thú vị nữa concurrency trong Erlang được xây dựng bởi các tiến trình chạy độc lập nhau do đó nó không có bất kỳ một khái niệm nào dể thay đổi cấp độ của ngôn ngữ hòng mang lại parallelism thật sự. Tất cả các thay dổi được thực hiện bên trong máy ảo, nơi mà lập trình viên không thể thấy được. là An interesting fact is that because Erlang concurrency is all about isolated processes, it took no conceptual change at the language level to bring true parallelism to the language. All the changes were transparently done in the VM, away from the eyes of the programmers.
Concepts of Concurrency

Trở lại thời trước đó, Erlang được phát triển vô cùng nhanh chóng, nó thường xuyện nhận được rất nhiều hỗ trợ và phản hồi từ những kỹ sư đã viết phần mêm cho Erlang trong các thiết bị chuyển mạch điện thoại ( telephone switch ). Chính những việc tương tác này đã chứng mình việc sử dụng processes-based concurrency và asynchronous message passing là một cách chính xác để giải quyết những vấn đề mà họ gặp phải. Hơn nữa, Trước khi Erlang xuất hiện, ngành công nghiệp điện thoại trên thế giới đã có một nền văn hóa thống nhất đói việc concurrency rồi. Back in the day, Erlang's development as a language was extremely quick with frequent feedback from engineers working on telephone switches in Erlang itself. These interactions proved processes-based concurrency and asynchronous message passing to be a good way to model the problems they faced. Erlang thực chất chỉ chỉ kế thừa những thành quả từ ngỗn ngữ PLEX mà thôi ( một ngữ ngữ đã được công ty Ericssion tạo ra trước đó cho các hệ thống điện thoại của ho) và AXE ( một thiết bị switch được phát triển trong ngôn ngữ PLEX), cơ bản nó chỉ kế thừa thành quả và cố gắng cải tiến từ những công cụ hiện có mà thôi.
Để Erlang được coi là môt công cụ tốt, thì bắt buộc nó phải đáp ứng được các yêu cầu sau: Phải có khả năng mở rộng ( scale up - đây là yêu cầu quan trọng nhất ) và hỗ trợ hàng ngàn người dùng trên nhiều thiết bị switch. và có tính ổn đinh ( reliability ) cao ( tới mức mà chương trình, ứng dụng không bao giờ được phép ngừng hoạt động) The main ones were being able to scale up and support many thousands of users across many switches, and then to achieve high reliability—to the point of never stopping the code.
Scalability
Đây là tính năng đâu tiên mà tôi sẽ tập trung vào giải thích. Chúng ta sẽ tìm hiểu một số các thuộc tính cần thiết để nhận được tính năng mở rộng này. Như đã biết Erlang trươc đó được sử dụng trên các thiết bị switch do đó trong Erlang, người dùng sẽ được quy ước bởi các tiến trình và chúng có nhiệm vụ đợi phản hồi các sự kiện nhất định (ví dụ như: nhận cuộc gọi, chờ máy, kết thúc cuộc gọi, etc...). Một hệ thống lí tưởng là hệ thống sẽ hô trợ việc tiến toán, xử lí một lượng nhỏ thông tin bởi các tiến trình, chuyển đổi nhanh chóng giữa chúng khi có một sự kiện xảy ra. Đê tăng tính hiệu quả, các tiến trình được tạo ra và hủy phải rất nhanh, thậm chí việc chuyển đổi giữa các tiến trình cũng phai nhanh chóng. Đê đảm bảo được điều này thì các tiến trình phải rất nhỏ và nhẹ. Ngoài ra nó cũng phải đảm bảo sao cho thiêt kế các chương trình để có thể sử dụng được nhiều tiến tiến trình khi cần thay vì sử dụng các bể tiến trinh ( process pool ) sẵn có ( bể tiến trình là khái niệm sử dụng một lượng tiến trình đã được đinh sẵn và các công viên có thể chuyển đổi qua lại giữa các tiến tiến trình trong bể này). I'll focus on the scaling first. Some properties were seen as necessary to achieve scalability. Because users would be represented as processes which only reacted upon certain events (i.e.: receiving a call, hanging up, etc.), an ideal system would support processes doing small computations, switching between them very quickly as events came through. To make it efficient, it made sense for processes to be started very quickly, to be destroyed very quickly and to be able to switch them really fast. Having them lightweight was mandatory to achieve this. It was also mandatory because you didn't want to have things like process pools (a fixed amount of processes you split the work between.) Instead, it would be much easier to design programs that could use as many processes as they need.
một khía cạnh quan trọng khác khác trong tính mở rộng là không phụ thuộc vào giới hạn phần cứng. Có phương án để làm được điều này: với cách thứ nhất khá đơn giản đó là chúng ta sử dụng, nâng cấp tài nguyên phần cứng tốt hơn đơn cử như tăng số lượng phần cứng lên. Đây là phương án dẽ nhất những nó có giơi hạn là chỉ giải quyết dược tại thời điểm nhất định, sau đó khi lượng tài nguyên lón dân lên, chúng ta lại phải nâng cấp, và chi phí sẽ càng tăng lên tất nhiều điều đó thật sự quá đắt đỏ ( ví dụ nhừ mua một một cỗ siêu máy tính). Phương án thứ hai, đây là một phương án thường xuyên được chọn bởi ví không tón kém quá nhiều chi phí. thay vì bạn phải nâng cấp phần cứng lên thì bạn chỉ cần tăng số lượng máy tính lên đê xử lí công việc. Và đây là tính năng phân tán ( distribution ) ,một phần của ngôn ngữ Erlang tỏa sáng. Another important aspect of scalability is to be able to bypass your hardware's limitations. There are two ways to do this: make the hardware better, or add more hardware. The first option is useful up to a certain point, after which it becomes extremely expensive (i.e.: buying a super computer). The second option is usually cheaper and requires you to add more computers to do the job. This is where distribution can be useful to have as a part of your language.
Dù sao, chúng ta hay quay lại vấn đề về các tiến trình nhỏ lúc trước đã đề cập tới. trong cách ứng dụng điện thoại lúc bấy giờ, chúng đòi đòi hỏi phải có tính ổn đinh cao. một trong nhưng nguyễn nhân mà ảnh hưởng tới tinh ổn định đó là việc sử dụng chung tài nguyên giữa các tiến trình và luồng, vì thế cách tốt nhất đó là ngăn không cho các tiến trình, luống chia sẽ bất kỳ vùng nhớ nào với nhau. Nếu vẫn cho phép chia sẻ vùng nhớ với nhau chúng ta sẽ phải đối mặt với một số tình huống không đông nhất trạng thái và dẫn tới crash chương trình, hệ thống ( đặc biệt chia sẽ dữ liệu giữa các nút, một khi crash có thể làm ảnh hưởng tới toàn bộ hê thống). Thay vào đó các tiến trình sẽ được chia sẽ , trao đổi thông tin với nhau bằng cách truyền các thông điệp cho nhau ( send messages ) và các dữ liệu chỉ đơn thuẩn là các bản sao. Cách làm này sẽ an toàn và giảm thiểu rủi ro hơn. because telephony applications needed a lot of reliability, it was decided that the cleanest way to do things was to forbid processes from sharing memory. Shared memory could leave things in an inconsistent state after some crashes (especially on data shared across different nodes) and had some complications. Instead, processes should communicate by sending messages where all the data is copied. This would risk being slower, but safer.
Fault-tolerance
tính chất thử hai cần trong Erlang đó là tính ổn định. Các nhà phát triển đầu tiên của Erlang luôn ghi nhớ rằng lỗi hỏng hóc luôn phổ biến, xảy ra ở khắp mọi nơi và không thể tránh khỏi, cho dù bạn có cố tìm cách dể tránh những bugs đó thì nó vẫn sẽ xảy ra thôi. thậm chí ngay cả không có bugs thì bạn vẫn không thể tránh khỏi lỗi phần cứng được. đó đó đề xuất tốt nhất được đưa ra đó là tìm ra phương án cách để giải quyết và xử lí các lỗi hơn là cố gắng ngăn chăn, tránh lỗi không xảy ra. This leads us on the second type of requirements for Erlang: reliability. The first writers of Erlang always kept in mind that failure is common. You can try to prevent bugs all you want, but most of the time some of them will still happen. In the eventuality bugs don't happen, nothing can stop hardware failures all the time. The idea is thus to find good ways to handle errors and problems rather than trying to prevent them all.
Chúng ta sẽ quay trở lại nói một số vấn đề đã nói lúc trước, hóa ra cách thiết kế làm việc với đa tiên trình ( multi proccesses ) và truyền thông điệp ( message passing ) là một ý tưởng tuyệt vời. Nó tương đối dễ dàng để tích hợp với việc xử lí lối. bằng cách sư dụng các tiểu trình ( lightweight processes - chúng được tạo ra, phục hồi và chấm dứt mộc cách nhanh chóng), một số nghiên cứu đã chỉ ra rằng các lôi gây downtime trong các mã nguồn, chương trình phần mềm có quy mô lớn thường là các lỗi ít khi xảy ra như intermittent bugs ( đây là những bug rất khó phát hiện một phần bởi vì nó đặc biệt chỉ xảy ra sau một vài trường hợp hoặc một lần chạy lại một đoạn mã) hoặc transient bugs ( đấy là những đôi xuất hiện đột ngột và cũng tự động biến mất vd như những lõi liên quan tới việc xử lí một việc nào đó trong thời gian quá dài gây ra việc timeout hay lỗi khi hệ làm làm việc qua tải ) (source). Vì vậy có một số quy tắc được dung để nói về những lỗi khiến cho dữ liệu bị corrupt mà làm cho một số bộ phân của hệ thống bị ảnh hưởng ( lỗi hoặc hỏng) lên được chấm dứt nhanh nhất có thể để tránh các dư liệu không tôt ( bad data ) và ảnh hưởng lan rộng tới các bộ phận , hệ thống khác, nguy hiểm là nó có thể gây sụp đổ toàn bộ hệ thống. Ngoài ra còn có một khái niệm khác mà theo đó có nhiều cách khác nhau, nhưng trong đó có hai cách phổ biến để kết thúc một hệ thống đó làm clean shutdown và crash ( chấm dứt hệ thống cùng với một lỗi không muốn ). It turns out that taking the design approach of multiple processes with message passing was a good idea, because error handling could be grafted onto it relatively easily. Take lightweight processes (made for quick restarts and shutdowns) as an example. Some studies proved that the main sources of downtime in large scale software systems are intermittent or transient bugs (source). Then, there's a principle that says that errors which corrupt data should cause the faulty part of the system to die as fast as possible in order to avoid propagating errors and bad data to the rest of the system. Another concept here is that there exist many different ways for a system to terminate, two of which are clean shutdowns and crashes (terminating with an unexpected error).
Rõ ràng rằng trường hợp xấu nhất là crash. nhung nếu có một giải pháp đảm bảo an toàn mà khiến tất cả đề crash mà kết quả lại tương tự như clean shutdown ? Để làm điều này chúng ta cần phải thực hiện thông qua một số thực tiến như không chua sẻ bất cứ thứ gì , một thứ chỉ được phép gán duy nhất một lần ( ý nghĩa cho việc các tiến trình độc lập với nhau), không có bất kỳ locks ( để tránh việc một việc một tiến trình đang lock xảy ra lỗi và nó sẽ không unlock việc đó khiến cho tất cả các tiến trình khác không thể truy cập vào được gây deadlock ) và một điều khác nữa nhưng không quan trọng lên tôi sẽ không mô tả chúng nhưng cũng nằm trong các thành phần thiêt kế của Erlang. Vì vậy giải pháp lí tưởng cho việc này dó là chấm dứt các tiến trình ( kill processes ) nhanh chóng để tránh lỗi dữ liệu và ngăn chăn sự xuất hiện các lỗi transient bugs ảnh hưởng tới hệ thống. Các tiểu trình chính là yêu tốt then chốt đống vai trò quan trọng trong việc này, Hơn nữa các cơ chế xử lí lỗi cũng góp phần trong việc giám sát các tiến trình khác ( chúng ta sẽ đi sâu hơn vào chúng trong chương Errors and Processes) để biết được tiến trình nào vừa mới chết cũng như quyết dịnh biện pháp xử lí đối với tiến trình đó. Here the worst case is obviously the crash. A safe solution would be to make sure all crashes are the same as clean shutdowns: this can be done through practices such as shared-nothing and single assignment (which isolates a process' memory), avoiding locks (a lock could happen to not be unlocked during a crash, keeping other processes from accessing the data or leaving data in an inconsistent state) and other stuff I won't cover more, but were all part of Erlang's design. Your ideal solution in Erlang is thus to kill processes as fast as possible to avoid data corruption and transient bugs. Lightweight processes are a key element in this. Further error handling mechanisms are also part of the language to allow processes to monitor other processes (which are described in the Errors and Processes chapter), in order to know when processes die and to decide what to do about it.
Gỉa sử rằng việc phục hồi nhanh chóng các tiến trình đủ giúp cho việc giải quyết các trường hợp khi crash,
thì chúng ta vẫn con một vấn đề khác nữa dó là lõi xảy ra liên quan tới phần cứng ( hardware failures ).
Liệu rằng bạn có đảm bảo rằng một chươn trình vẫn sẽ chạy tốt hay ít nhất đang chạy khi có một ai đó bỗng dưng đạp vào cái máy tính mà chương trình đang hoạt động trên nó ?
 Mặc dù bạn có thể ngăn chặn điều này bằng cách thiết lập một cơ chế phòng vệ bằng cách sử dụng laser để phát hiện và đặt các chậu xương rồng xung quanh
đó, nhưng như vậy là không đủ. Có một gợi ý đơn giản , dễ dang đó là bạn có thể chạy cùng một chương trình trên nhiều máy tính như thế sẽ đảm nếu một ai đó đá vào thì
vẫn có máy khác chạy chương trình đó và mọi thứ vẫn hoạt động bình thường. với việc sủ dụng hệ thông phần tán và độ lập các tiến trình,
bạn có một lợi thế khác của các tiến trình độc lập đó là việc giao tiếp giữa chúng chỉ thông qua duy nhất là truyền thông điệp ( message passing ).
Dựa vào đó các tiến trình có thể giao tiếp với nhau tương tự với cả trên cùng máy tính hay trên các máy tính khác nhau,
making fault tolerance through distribution nearly transparent to the programmer.
Mặc dù bạn có thể ngăn chặn điều này bằng cách thiết lập một cơ chế phòng vệ bằng cách sử dụng laser để phát hiện và đặt các chậu xương rồng xung quanh
đó, nhưng như vậy là không đủ. Có một gợi ý đơn giản , dễ dang đó là bạn có thể chạy cùng một chương trình trên nhiều máy tính như thế sẽ đảm nếu một ai đó đá vào thì
vẫn có máy khác chạy chương trình đó và mọi thứ vẫn hoạt động bình thường. với việc sủ dụng hệ thông phần tán và độ lập các tiến trình,
bạn có một lợi thế khác của các tiến trình độc lập đó là việc giao tiếp giữa chúng chỉ thông qua duy nhất là truyền thông điệp ( message passing ).
Dựa vào đó các tiến trình có thể giao tiếp với nhau tương tự với cả trên cùng máy tính hay trên các máy tính khác nhau,
making fault tolerance through distribution nearly transparent to the programmer.
Although a fancy defense mechanism comprising laser detection and
strategically placed cacti could do the job for a while, it would not last forever. The hint is simply to have your program running on more than one computer at once,
something that was needed for scaling anyway. This is another advantage of independent processes with no communication channel outside message passing. You can have them working
the same way whether they're local or on a different computer, making fault tolerance through distribution nearly transparent to the programmer.
Tuy vậy việc sủ dụng khả năng phân tán trực tiếp cũng có những rào cản nhất định ảnh hưởng quan trọng tới việc các tiến trình có thể giao tiêp với nhau như thê nào. Một trong những rào cản lớn nhất đó là chúng ta không thể đảm bảo rằng một node ( hay một máy tính từ xa khác) luôn luôn sẵn sàng hoạt động khi bạn gọi một hàm tới nó, có thể nó vẫn hoạt động trong suốt quá trình truyền tải của lời gọi hay lời gọi đó hoàn toàn chính xác. Ai mà biết tại thời điểm đó có một ai đó lỡ chân vấp vào dây cắm điện, tắt nhầm máy tính hay ứng dụng của bạn đạng treo hoặc không hoạt động ?.
Being distributed has direct consequences on how processes can communicate with each other. One of the biggest hurdles of distribution is that you can't assume that because a node (a remote computer) was there when you made a function call, it will still be there for the whole transmission of the call or that it will even execute it correctly. Someone tripping over a cable or unplugging the machine would leave your application hanging. Or maybe it would make it crash. Who knows?Điều nảy chỉ ra rằng việc lựa chọn xử lí bất đồng bộ tin nhắn là môt thiết kế tốt. Dựa trên mô hình processes-with-asynchronous-messages ( các tiến trình giao giao tiếp với nhau qua cơ chế gửi tin nhắn mà không yêu cầu chờ phản hồi ), các tin nhắn sẽ đữo gửi tới từ môt tiến nỳ sang một tiến trình khác và được lứu trữ trong một hòm thư ( mailbox ) của tiến trình được nhận được, và chúng cứ lưu trữ như vậy cho tới khi chúng được lấy ra để đọc. Một điều khá quan trọng cần nói tới đó là các tin nhắn đươc gửi đi sẽ không cần phải kiểm tra để biết tiến trình nhận có tồn tại hay không vì thật sự không có lợi gì từ việc kiểm tra nay hơn nữa quá trình kiểm tra cũng có thể ảnh hưởng tới hiệu suất và dễ phát sinh lỗi. Như đã đề cập trước đó, không thể biết trước một tiến trình có tồn tại hay đã crash trong khoản thời gian một tin nhắc được gửi đi và nhận được, trong trường hợp nếu nó nhận được tin nhắn cùng không thể biết được nếu một lần nữa tin nhắn được gửi đi thì tiến trình nhận vẫn còn tồn tại hay không. các tin nhắn bất đồng bộ ( Asynchronous messages ) cho phép gọi các hàm từ xa một cách an toàn bởi vì không có bất kỳ giả định nào về điều gì sẽ xảy ra. chi có duy nhất lập trình biên là người biết được điều gì sẽ xảy ra. Trong trường hợp nếu bạn muốn có một sự xác nhận là đã gửi tin nhắn thành công, bạn sẽ phải tạo ra một tin nhắn từ tiến trình nhận và gửi phản hồi lại tới tiên trình gôc ( tiến trình gửi tin nhắn đi ), và đối với tin này này cũng như bất kỳ chương trình hay thư viên nào bạn xây dựng cũng đều phải tuân theo ngữ nghĩa mang tính an toàn. Well it turns out the choice of asynchronous message passing was a good design pick there too. Under the processes-with-asynchronous-messages model, messages are sent from one process to a second one and stored in a mailbox inside the receiving process until they are taken out to be read. It's important to mention that messages are sent without even checking if the receiving process exists or not because it would not be useful to do so. As implied in the previous paragraph, it's impossible to know if a process will crash between the time a message is sent and received. And if it's received, it's impossible to know if it will be acted upon or again if the receiving process will die before that. Asynchronous messages allow safe remote function calls because there is no assumption about what will happen; the programmer is the one to know. If you need to have a confirmation of delivery, you have to send a second message as a reply to the original process. This message will have the same safe semantics, and so will any program or library you build on this principle.
Implementation
Được rôi, Cơ bản quyết định của việc sử dụng tiểu trình và tin nhắn bát đồng bộ là hoàn toàn phù hợp với Erlang. Nhưng làm thế nào để tạo ra ? Để làm được , trước tiên chúng ta không lên tin tưởng để hệ điều hành quản lí các tiến trình này. Mặc dù hệ điều hành có rất nhiều cách khác nhau để quản lí các tiến trình, và hiệu suất quản lí của mỗi cách đều khác nhau nhiều, nhưng có một điểm chung là hầu hết tất cả đều quản lí rất chậm hay các tiến trình quá nặng trong khi những gì mà Erlang cần thì nó lại không đáp ứng được. Vì vậy chúng đã được chuyển qua cho máy ảo Erlang đảm nhiệm, bằng cách này, những nhà phát triển Erlang có đảm bảo được việc tối ưu và tính ổn định. Tinh tới thời điểm này, mỗi tiên trình của Erlang sẽ tiêu tốn khoảng 300 words cho bộ nhớ và chỉ mất vài phần nghìn giây để tạo ra điều mà khó thấy được ở hầu hết các hệ điều hành ngày nay. lightweight processes with asynchronous message passing were the approach to take for Erlang. How to make this work? Well, first of all, the operating system can't be trusted to handle the processes. Operating systems have many different ways to handle processes, and their performance varies a lot. Most if not all of them are too slow or too heavy for what is needed by standard Erlang applications. By doing this in the VM, the Erlang implementers keep control of optimization and reliability. Nowadays, Erlang's processes take about 300 words of memory each and can be created in a matter of microseconds—not something doable on major operating systems these days.
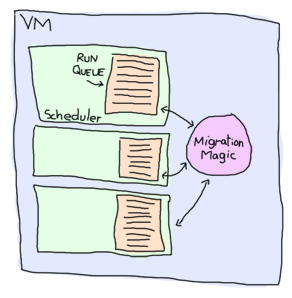
để quản lí và thao tác với tất cả các tiến trình được sinh ra từ chương trình của bạn, Máy ảo Erlang sẽ tạo ra một luồng ( thread ) trong mỗi lỗi ( core ) và ta có thể coi như một bộ lập lịch ( scheduler ). Trong mỗi bộ lập lịch sẽ có một hàng đợ ( run queue ) , đây là một danh sách các tiến trình được lâp lich phan phối ở các khoảng thời gian có thể cùng nhau hay khác nhau. Trong trường hợp khi mà hàng đợi của một bộ lập lịch chứa quá nhiều tasks, thì nó sẽ tự động dịch chuyển sang các hàng đợi khác mà vẫn còn trống. Đây là một trong những cơ chế cân bằng tải ( load-balancing ) của Máy ảo Erlang giúp cho việc tự động quản lí các tasks tốt hơn và lập trình viên không cần phải quan tâm tới vấn đều này mà chỉ cần tập trung vào xử lí các task thôi. Tuy nhiên trong trường hợp khi mà tât cả các hàng đợi của các bộ lập lịch đều không thể chứa được nữa, khi đó chúng ta phải áp dụng một cơ chế khác để giải quyết vấn đề này , tôi sẽ đề cập chi tiết tới nó sau). Ngoài ra việc tối ưu hóa cũng có thể được thực hiện, vd như bạn có thể giới hạn số lượng tin nhắc gửi tới các tiến trình đang quá tải để điều trình và phân tán lại lượng tin nhắc giữa các tiến trình. To handle all these potential processes your programs could create, the VM starts one thread per core which acts as a scheduler. Each of these schedulers has a run queue, or a list of Erlang processes on which to spend a slice of time. When one of the schedulers has too many tasks in its run queue, some are migrated to another one. This is to say each Erlang VM takes care of doing all the load-balancing and the programmer doesn't need to worry about it. There are some other optimizations that are done, such as limiting the rate at which messages can be sent on overloaded processes in order to regulate and distribute the load.
Tất cả nhũng phần khó khăn máy ảo Erlang đã quản lí giúp bạn rồi. Nhờ vậy thật dễ dàng khi bạn muốn thực hiện các công việc song song ( parallel ) với Erlang. Chạy song song Vậy chạy song song có nghia là chương trình của bạn chạy chạy nhanh gấp hai lần nếu bạn thêm một lõi vào, gâp bốn nếu có hay nhiều hơn 4 lõi, đúng không ? Không hẳn nó tùy thuộc vào tình huống. Dĩ nhiên là tốc độ , hiệu suất chương trình sẽ hơn bơi số lõi nhưng nó còn tuân theo một nguyên tắc được gọi là mở rộng tuyến tính ( linear scaling ) ( xem biểu dồ bên dưới ) . Chắc hẳn bạn đã từng nghê tới câu nói: trên đơi này chẳng có bữa trưa nào là miễn phí! ( hm có thể ở đám tang, nhưng một vài người vẫn phải trả ). All the hard stuff is in there, managed for you. That is what makes it easy to go parallel with Erlang. Going parallel means your program should go twice as fast if you add a second core, four times faster if there are 4 more and so on, right? It depends. Such a phenomenon is named linear scaling in relation to speed gain vs. the number of cores or processors (see the graph below.) In real life, there is no such thing as a free lunch (well, there are at funerals, but someone still has to pay, somewhere).
Not Entirely Unlike Linear Scaling
Mở rộng tuyến tính không hẳn là khó do nó phụ thuộc vào ngôn ngữ mà còn bởi chính những vấn để trong thực tế cần phải giải quyết. Các vấn đê này thường được nhắc tới như embarrassingly parallel nếu bạn thử tìm kiếm những vấn đề về embarrassingly parallel trên mạng Internet. bạn sẽ thấy một số ví dụ như ray-tracing ( một phương pháp tạo ảnh 3 chiều ), vét cạn để dò khóa trong mã hóa hay như dữ đoán thời tiết, etc.
The difficulty of obtaining linear scaling is not due to the language itself, but rather to the nature of the problems to solve. Problems that scale very well are often said to be embarrassingly parallel. If you look for embarrassingly parallel problems on the Internet, you're likely to find examples such as ray-tracing (a method to create 3D images), brute-forcing searches in cryptography, weather prediction, etc.Thỉnh thoảng, trên các kệnh IRC, diễn đàm và mailing lists lại xuất hiện một vài câu hỏi về vấn đề này liệu Erlang có thể giải quyết được chúng không ? hay liệu có thể sử dụng được GPU. Câu trả lời cho các câu hỏi như vậy là 'không'. giải thích cho lí do này là bởi vì tât cả những vẫn đề đó thường sử dụng một số thuật toán số học để phân tích một lượng lớn dữ liệu. Việc này cần tới khả năng xử lí nhanh và xử lí các tác vụ nặng điều mà Erlang không thực sự tốt trong các trường hợp như vậy. From time to time, people then pop up in IRC channels, forums or mailing lists asking if Erlang could be used to solve that kind of problem, or if it could be used to program on a GPU. The answer is almost always 'no'. The reason is relatively simple: all these problems are usually about numerical algorithms with lots of data crunching. Erlang is not very good at this.
Các vấn đề embarrassingly parallel trong Erlang thường biểu hiện ở mức độ logic cao hơn, thông thường, chúng thường xuyên được sử dụng trong các khái niệm về chat server, phone switch, web servers, message queues, web crawlers hay bất kỳ các ứng dụng nào mà có thể biểu diễn dưới các thực thể logic độc lập ( actors, anyone?). Tuy nhiên chúng ta có thể giải quyết chúng một cách hiệu hơn với close-to-linear scaling.
Erlang's embarrassingly parallel problems are present at a higher level. Usually, they have to do with concepts such as chat servers, phone switches, web servers, message queues, web crawlers or any other application where the work done can be represented as independent logical entities (actors, anyone?). This kind of problem can be solved efficiently with close-to-linear scaling.Tuy nhiên không phải lúc có có được tính mở rộng, thực tế bạn sẽ không đạt được tính chất này trong một số hoạt động , Vd như khả năng mở rộng sẽ mất hay giảm xuống nếu có một chuỗi tuần tự các hoạt động tập trung, Khi đó chương trình chạy song song của bạn cũng chỉ ngang bằng một phần tiếp nối chạy chậm nhất mà thôi. xét một vd trong cụ thể đời sống, bạy hãy để ý quan sát ở bất kỳ siêu thị, tại một quầy có hàng trăm người đang trong quầy để mua sắm, sau khi lựa được hàng mình muốn muốn , từng người sẽ tiến quầy thanh toán. Sẽ không có gì nếu thởi điểm thanh toán có một vài ngừoi nhưng khi số lượng người thanh toán ngày một nhiều, họ sẽ phải xếp hàng chờ, khi đó một hàng đợi sẽ được lập ra khi lượng ngừoi thanh toán lớn hơn nhân viên thu ngân đang có tại quầy hàng đó. Many problems will never show such scaling properties. In fact, you only need one centralized sequence of operations to lose it all. Your parallel program only goes as fast as its slowest sequential part. An example of that phenomenon is observable any time you go to a mall. Hundreds of people can be shopping at once, rarely interfering with each other. Then once it's time to pay, queues form as soon as there are fewer cashiers than there are customers ready to leave.
Trong trường hợp đó, bạn có thêm gọi thêm nhân viên thu ngân để phục vụ mỗi khách, nhưng đồng thời bạn cũng sẽ phải cần có thêm những cánh cửa để khách hàng ra khỏi quầy sau khi thanh toán xong ( không một cánh của nào đủ lớn để tất cả khách hàng cùng vào hay ra trong 1 lần được ). It would be possible to add cashiers until there's one for each customer, but then you would need a door for each customer because they couldn't get inside or outside the mall all at once.
Nói một cách khác, các khách hàng có thể song song tùy ý chọn lựa vật phẩm và mất nhiều thời gian để lựa chọn ko kể số lượng, nhưng cuối cùng họ vân phải xếp hàng chờ để thanh toán. Có thể nói dựa trên kinh nghiệm mua sắm của họ thì không bao giờ ngắn hơn thời gian mà họ phải chờ hay thanh toán. To put this another way, even though customers could pick each of their items in parallel and basically take as much time to shop whether they're alone or a thousand in the store, they would still have to wait to pay. Therefore their shopping experience can never be shorter than the time it takes them to wait in the queue and pay.
Một sự tổng quát của nguyên tắc này được gọi là Dinh luật Amdahl (Amdahl's Law ). Trong nguyên tắc này luôn chỉ ra mối liên hệ giữa tốc độ mỗi khi bạn thêm khả năng song song ( parallelism ) vào. A generalisation of this principle is called Amdahl's Law. It indicates how much of a speedup you can expect your system to have whenever you add parallelism to it, and in what proportion:

Theo thuyết định luật này, bất kể thế nào khi ̀50% đoạn mã của bạn thực hiện song song thì cho dù bạn có thêm bao nhiều số lỗi hay thread vào thì nó nhanh được hơn gấp đôi so với trước đó, và khi 95% đoạn mã của bạn thưc hiện song song thì theo lí thuyết chương trình sẽ này hơn khoảng 20 lần so với trước, trong điều kiện bạn sử dụng đủ số cpu. Thật thú vị khi nhìn vào đồ thị này ta tháy rằng việc loại bỏ một vài phần không song song của chương trình về mặt lí thuyết lại cải thiện tóc độ của chương trình hơn khi so với loại bỏ các đoạn mã chạy tuần tự trong chương trình mà không chạy song song. . code that is 50% parallel can never get faster than twice what it was before, and code that is 95% parallel can theoretically be expected to be about 20 times faster if you add enough processors. What's interesting to see on this graph is how getting rid of the last few sequential parts of a program allows a relatively huge theoretical speedup compared to removing as much sequential code in a program that is not very parallel to begin with.
Don't drink too much Kool-Aid:
Parallelism thì không phải là cách giải quyết đôi với mọi vân đề. Một số trường hợp việc áp dụng song song còn khiến chương trình của bạn chậm hơn.
nhất là khi toàn bộ chương trình của bạn yêu cầu xú lí tuần tự ( 100% code ) nhưng bạn lại sử dụng đa tiến trình để chạy song song.
the answer to every problem. In some cases, going parallel will even slow down your application. This can happen whenever your program is 100% sequential,
but still uses multiple processes.
Một trong những ví dụ cụ thể minh họa tốt nhất cho vấn đề này đó là ring benchmark. ring benchmark là một chương trình kiêm thử với việc sử dụng hàng ngàn tiến trình truyền dữ liệu tuần tự với nhau thành một vòng tròng hoặc bạn có thể hình dung tới trò chơi game of telephone. trong kết quả thử nghiệm đấy, nó chỉ rõ chỉ rằng một tiến trình thực sự hũu ích khi được xử lí tại một thời điểm , nhưng Máy ảo Erlang vẫn danh rất nhiều thời gian để phân tán giữa các lõi và chia sẽ thời gian giữa các tiến trình. One of the best examples of this is the ring benchmark. A ring benchmark is a test where many thousands of processes will pass a piece of data to one after the other in a circular manner. Think of it as a game of telephone if you want. In this benchmark, only one process at a time does something useful, but the Erlang VM still spends time distributing the load accross cores and giving every process its share of time.
Việc làm này làm ảnh hưởng rất nhiều tới việc tối ưu hóa phần cứng, khiến cho máy ảo mất nhiều thời gian ở những công việc không đem lại hiệu quả.
Và nó dẫn tới việc một ứng dụng thuần chạy tuần tự sẽ chạy chậm hơn nhiều trên một máy tính đa lỗi hơn là máy tính chỉ có một lõi.
Do đó trong trường hợp này , bắt buôc chúng ta phải vô hiệu hóa tính năng symmetric multiprocessing $ erl -smp disable) đi để chương trình chạy tốt hơn.
$ erl -smp disable) might be a good idea.
So long and thanks for all the fish!
Chúng ta đã tìm hiểu khái khát mỗi liên hệ giữa concurrency và paraleíms rồi, và tất nhiên là chương này vẫn chua thể hoàn thành nếu chúng ta không hiểu và thấy được vd về 3 cơ chế để tạo lên concurrency trong Erlang: bào gồm khởi tạo, sinh ra một tiến trình mới ( spawning new processes ), gửi các tin nhắn ( sending messages ), nhận các tin nhắc ( receiving messages ). Ngoài ra còn nhiều cơ chế khác góp phần tạo lên một ứng dụng ôn định nhưng hiện tại chúng ta sẽ chỉ đi và 3 thành phần kia thôi.
Of course, this chapter would not be complete if it wouldn't show the three primitives required for concurrency in Erlang: spawning new processes, sending messages, and receiving messages. In practice there are more mechanisms required for making really reliable applications, but for now this will suffice.Từ đầu tới giờ tôi đã bỏ qua việc giải thích thế nào là một tiến trình, thực tế nó không có nhiều, về cơ bản tiến trình trong Erlang chỉ coi là một hàm thôi. Tiến trình sẽ được sinh ra khi bạn chạy một hàm và sẽ tự động biến mát khi hàm đó kết thức. Còn về mặt chuyên môn kỹ thuật, thì một tiến trình được hiểu như một trạng thái ẩn nào đó ( vd giống như một hòm thư), nhưng hiện tại chúng ta hiểu tiến trình là một hàm là đủ.
I've skipped around the issue a whole lot and I have yet to explain what a process really is. It's in fact nothing but a function. That's it. It runs a function and once it's done, it disappears. Technically, a process also has some hidden state (such as a mailbox for messages), but functions are enough for now.Để tao ra một tiến trình, Bạn sẽ gọi hàm spawn/1, hàm này nhận một tham số đầu vào là một hàm khác, hay nói cách khác
đâu là một higher older function.
spawn/1, which takes a single function and runs it:
1> F = fun() -> 2 + 2 end. #Fun<erl_eval.20.67289768> 2> spawn(F). <0.44.0>
Nhìn vào kêt quả của vd khi gọi hàm spawn/1 (<0.44.0>), bạn sẽ thấy một chuối ky tự số,
đây chính định danh của tiến trình (Process Identifier), viết tắt là PID, Pid, hay pid.
đinh danh của tiến trình được biểu diễn dưới dạng một chuối giá trị tùy ý đối với bất kỳ tiến trình nào đã và đang tồn tại
tại thời điểm mà máy ảo đang hoạt động. các đinh danh này chính là địa chỉ để các tiến trình giao tiếp với nhau.
Lưu ý là chúng ta không thể thấy được kết quả của hàm F. Thay vào đó chúng ta chỉ nhận được một đinh danh ( pid ). Đó là bởi vì các tiến trính sẽ không trả lại bất cứ gì cả.
Vậy làm thế nào để ta nhận được kết quả từ hàm F ? Hm có hai cách để nhận được kết quả. Cách đầu tiến là luôn hiển thị ( output ) bất kỳ gì mà chúng ta cần , đây là cách dễ dàng nhất:
3> spawn(fun() -> io:format("~p~n",[2 + 2]) end).
4
<0.46.0>
Mặc dù đây không phải là một chương trình thực sự, nhưng nó sẽ giúp chúng ta thấy cách tổ chức của các tiến trình.
Một đièu tuyệt vời nữa là bằng việc sử dụng hàm io:format/2, cũng đủ để chúng ta làm việc được.
hay xét một vd, chúng ta sẽ nhanh chóng tạo ra 10 tiến trình, sau đó ngừng chúng lại trong một khoảng thời gian nhờ vào
hàm timer:sleep/1, hàm này sẽ nhận một tham số đầu vào thuộc kiểu số nguyên, ở đây ta dung N là một giá trị số nguyên
để chỉ thời gian tho đơn vị mili giây, chúng ta sẽ ngừng các tiến trong N giây trước khi nó phục hôi lại.
Sau khoảng thời gian trễ đó, giá trị của tiến trình sẽ được hiển thị ra màn hình.
4> G = fun(X) -> timer:sleep(10), io:format("~p~n", [X]) end.
#Fun<erl_eval.6.13229925>
5> [spawn(fun() -> G(X) end) || X <- lists:seq(1,10)].
[<0.273.0>,<0.274.0>,<0.275.0>,<0.276.0>,<0.277.0>,
<0.278.0>,<0.279.0>,<0.280.0>,<0.281.0>,<0.282.0>]
2
1
4
3
5
8
7
6
10
9
Dường như thứ tự của các con số lộn xộn hết cả. Xin chúc mừng bạn là bạn đã đấu bước vào một thế giới mới, thế giới song song. Lí giải cho thứ tự kia về mặt logic là bởi vì các tiến trình cùng chạy đông thời một lúc, do đó thứ tự các sự kiện không được bảo toàn nữa. còn về mặt hệ thống là do máy ảo Erlang sử dụng một số điều chỉnh để xác định điểm khởi đầu của một tiến trình, sao cho các tiến trình được đảm bảo đủ thời gian để bắt đầu. Hầu hết các dịch vụ trong Erlang ( Erlang service ) đều là các tiến trình, bao gồm cả shell bạn hay sử dụng bản chất cũng là một tiến trình. Các tiến trình trong hệ thống của bạn phải được cân bằng với các hệ thống mà nó cần, điều này gây ra trật tự bị xáo trộn như ta thấy. The order doesn't make sense. Welcome to parallelism. Because the processes are running at the same time, the ordering of events isn't guaranteed anymore. That's because the Erlang VM uses many tricks to decide when to run a process or another one, making sure each gets a good share of time. Many Erlang services are implemented as processes, including the shell you're typing in. Your processes must be balanced with those the system itself needs and this might be the cause of the weird ordering.
Lưu ý: bất kể bạn có thiết lập hay vô hiệu hóa symmetric multiprocessing hay không thì kết quả xử lí vẫn không bị ảnh hưởng, chúng vẫn như nhạu.
Để chứng tỏ đièu này, bạn có thể kiểm tra bằng cách khởi động máy ảo Erlang bằng câu lệnh $ erl -smp disable.
$ erl -smp disable.
và để phần biệt giữa một máy ảo Erlang có hay không sử dụng SMP, hay tạo một máy ảo erlang cũng hay không cùng dòng lệnh phía trên kia và nhìn vảo dòng thông báo đầu tiên. Nếu dòng thông báo đó có kèm dòng chữ [smp:2:2] [rq:2], điều đó có nghĩa là máy ảo bạn đang chạy đang thiết lập cùng SMP và nó có hai hàng đợi (rq hay bộ lập lịch ) đang chạy trong 2 lõi. Còn nếu bạn nhìn thấy dòng chữ [rq:1], tức là bạn đã vô hiệu hóa SMP trong máy ảo rồi. To see if your Erlang VM runs with or without SMP support in the first place, start a new VM without any options and look for the first line output. If you can spot the text [smp:2:2] [rq:2], it means you're running with SMP enabled, and that you have 2 run queues (rq, or schedulers) running on two cores. If you only see [rq:1], it means you're running with SMP disabled.
Nêu bạn tò mò muốn biết ý nghĩa của [smp:2:2], thi đây là dòng thông báo cho bạn bạn rằng máy ảo bạn đang chạy cùng với hai lỗi và hay bộ lập lịch sẵn có. với [rq:2] tức là có hai hàng đợi đang hoạt động. Trong các phiên bản dầu tiên của Erlang, bạn có thể có nhiều bộ lập lịch nhưng chỉ có duy nhất một hàng đợi chia sẻ công việc. Từ sau phiên bản R13B, mặc dịnh mỗi bộ lập lịch sẽ kèm theo một hàng đợi cho nó để tăng tính hiệu quả khi xử lí xong xong. If you wanted to know, [smp:2:2] means there are two cores available, with two schedulers. [rq:2] means there are two run queues active. In earlier versions of Erlang, you could have multiple schedulers, but with only one shared run queue. Since R13B, there is one run queue per scheduler by default; this allows for better parallelism.
Như đã nói phía trên bản chất shell của Erlang cũng chỉ là một tiến trình, và để chừng mình điều này ,
tôi sẽ sử dụng hàm xây dựng sẵn self/0 để in ra pid của tiến trình hiện tại.
To prove the shell itself is implemented as a regular process, I'll use the BIF self/0, which returns the pid of the current process:
6> self(). <0.41.0> 7> exit(self()). ** exception exit: <0.41.0> 8> self(). <0.285.0>
Bạn có thể thấy pid đã thay đổi sau khi chấm dứt tiến trình hiện tại. Chi tiết của việc thay đổi này chúng ta sẽ nói tới sau. Còn giờ chúng ta chỉ tập chung những phần kiến thức cơ bản thôi. Trước tiên, một trong những quan trọng nhất để tìm hiểu đó là cách mà các tiến trình gửi tin nhắn qua lại với nhau ra sao, chắc hẳn không một ai muốn lúc nào cũng hiển thị kết quả giá trị của các tiến trình để lấy thông tin từ đố để nhập thủ công vào cho các tiến trình khác ( ít nhất là tôi sẽ không làm vậy ). And the pid changes because the process has been restarted. The details of how this works will be seen later. For now, there's more basic stuff to cover. The most important one right now is to figure out how to send messages around, because nobody wants to be stuck with outputting the resulting values of processes all the time, and then entering them by hand in other processes (at least I know I don't.)
Như đã đề cập từ nhũng chương đầu các tiến trình sẽ giao tiếp với nhau thông qua việc gửi và nhận các tin nhắn, và để làm điều này
trong Erlang chúng ta sẽ sử dụng toán tử ! hay còn được gọi với cái tên là bang.
Trong toán tử này phía trến trái của nó sẽ là một đinh danh của tiến trình ( pid ) và giá trị bên phải nó là một kiểu dữ liệu bất ký.
dữ liệu này sẽ được gửi tới tiến trình thông qua pid của nó.
The next primitive required to do message passing is the operator !, also known as the bang symbol.
On the left-hand side it takes a pid and on the right-hand side it takes any Erlang term. The term is then sent to the process represented by the pid, which can access it:
9> self() ! hello. hello
Nhìn vào ví dụ trên ta thấy một tin nhắn với giá trị là một atom được gửi đi, và vì chúng ta mới thực hiện
gửi đi mà không thực hiện bất kỳ một hoạt động nào để lấy tin nhắc đó ra lên chúng sẽ được đẩy vào hom thư ( mailbox ) trong tiến trình nhận.
bạn sẽ thắc mắc là vì sao dòng chữ hello được in ra ngay khi tin nhắc đã được gửi ?
đó là giá trị trả về của hoạt động gửi tin nhắn đi. Dựa vào cách trên và việc sử dụng toán tử !, bạn có thể gửi
tin nhắc tới bao nhiêu tiến trình khác cũng được.
The message has been put in the process' mailbox, but it hasn't been read yet.
The second hello shown here is the return value of the send operation.
This means it is possible to send the same message to many processes by doing:
10> self() ! self() ! double. double
điều gì sẽ xảy ra khi bạn thực hiện câu lệnh này self() ! (self() ! double),
ah nó tương tự như biểu thức self() ! double. Ngoài ra có một điều lưu ý đối với hòm thư của một tiến trình, khi bạn truyền các tin nhắn tói một tién trình xác định
các tin nhắc sẽ được đặt vào trong hòm mail theo một thứ tự xác định theo cách mà chúng tới nó tương đương vd minh hoa giữa người và các bức thư
mà chúng ta sử dụng trong chương giới thiệu. Một khi mà tin nhắn được lấy ra để đọc, nó sẽ tìm tới hòm thư và lấy ra từng tin nhắc theo thứ tự mà chúng tới ( tin nhắc nào đến trước sẽ được lấy ra đọc trước ).
Which is equivalent to self() ! (self() ! double). A thing to note about a process' mailbox is that the messages are kept in the order they are received.
Every time a message is read it is taken out of the mailbox.
Again, this is a bit similar to the introduction's example with people writing letters.

Trong shell, để lấy tất cả nội dung tin nhắc được gửi tới hòm thư của một tinh trình bạn gọi tới hàm flush():
11> flush(). Shell got hello Shell got double Shell got double ok
Tuy nhiên Đây chỉ là hàm dùng để hiển thị tất cả cá tin nhăn ra màn hình thôi, chúng ta vẫn chưa thể lấy các giá trị của tiến trình để gán vào một biên được. Nhưng ít ra thì chúng ta đã biết được cách để gửi tin nhắn từ một tiến trình và kiểm tra tin nhắn đó có tồn tại trong hòm thư hay không. This function is just a shortcut that outputs received messages. This means we still can't bind the result of a process to a variable, but at least we know how to send it from a process to another one and check if it's been received.
Thật sự là không có ý nghĩa gì nếu bạn gửi đi các tin nhắn mà chả ai quan tâm , thèm đọc cả, giống như việc bạn viết một
bài chủ sử dụng toàn biểu tượng emo vậy. Đó là lí do vì sao chúng ta cần tới biểu thức receive.
Nào nãy giờ chúng ta đã làm việc qua đủ trong shell ròi, giờ hay tạo ra một chương trình đơn giản và đặt chúng vào một file
dolphins.erl, chương trình của chúng ta sẽ chỉ đơn giản là dựa trên ý tưởng một con cá heo đang học thôi.
Sending messages that nobody will read is as useful as writing emo poetry; not a whole lot.
This is why we need the receive statement.
Rather than playing for too long in the shell, we'll write a short program about dolphins to learn about it:
-module(dolphins).
-compile(export_all).
dolphin1() ->
receive
do_a_flip ->
io:format("How about no?~n");
fish ->
io:format("So long and thanks for all the fish!~n");
_ ->
io:format("Heh, we're smarter than you humans.~n")
end.
Như bạn thấy, biểu thức receive có cú pháp và cách sử dụng giống với biểu thức case ... of mà trước đó chúng ta đã học.
khớp mẫu vận được sử dụng tương tự ( bạn vẫn có thể sử dụng chốt canh trong các mẫu ) chỉ khác một điều là các biến sẽ nhận các giá trị từ tin nhắc thay vì một biểu thức như case và of.
case and of.
Receives can also have guards:
receive
Pattern1 when Guard1 -> Expr1;
Pattern2 when Guard2 -> Expr2;
Pattern3 -> Expr3
end
Nào giờ chúng sẽ biên dịch module và kiểm tra nó:
11> c(dolphins).
{ok,dolphins}
12> Dolphin = spawn(dolphins, dolphin1, []).
<0.40.0>
13> Dolphin ! "oh, hello dolphin!".
Heh, we're smarter than you humans.
"oh, hello dolphin!"
14> Dolphin ! fish.
fish
15>
Trong đoạn kiểm tra trên, chúng ta sẽ làm quen với một cách mới để tạo ra một tiến trình bằng việc gọi hàm spawn/3, thay vì sử dụng spawn/1 và tryền vào một anonymous function.
Hàm spawn/3 sẽ nhận 3 tham số đầu vào trong đó theo thứ tự là module, tên hàm và đối các số truyền vào hàm viết dưới một danh sách, bằng cách dùng hàm này
chúng ta sẽ tạo ra một đoạn mã gọn hơn so với trước. Một khi bạn chạy hàm đó nó sẽ thực hiện theo quy tắc sau:
Rather than taking a single function, spawn/3 takes the module,
function and its arguments as its own arguments. Once the function is running, the following events take place:
- đầu tiên nó sẽ chạy tới biểu thức
receive. tiếp đó nó sẽ kiểm tra hòm thư , và nếu hòm thư trống, hàm dolphin của chúng ta sẽ chờ một tin nhắn mới dược đẩy vào hòm thư. Given the process' mailbox is empty, our dolphin waits until it gets a message; - một tin nhắc với nội dung "oh, hello dolphin!" được gửi đi và tới hòm thư, và đươc hàm dolphin lấy ra để đọc.
khi lấy tin nhắc ra, nó sẽ khóp nội dung của tin nhắn đó với các mẫu đã định nghĩa trong 'receive', đầu tiên nó sẽ cố gắng kiểm tra để khớp với
mẫu
do_a_flip, nếu không đúng nó sẽ di chuyển tới mấu tiếp theo làfish, tiếp tục không khớp, nó sẽ tìm tiếp các mẫu tiếp theo, cho tới mẫu cuối cùng chúng ta sử dụng một mẫu để bắt tất cả các giá trị mà ko khớp với cá mẫu trước dó (_). Ở mẫu cuối cùng được khớp chính xác, tiến trình sẽ hiẻn thị ra màn hình nội dung "Heh, we're smarter than you humans.".
is received. The function tries to pattern match against - The process outputs the message "Heh, we're smarter than you humans."
do_a_flip. This fails, and so the pattern fish is tried and also fails.
Finally, the message meets the catch-all clause (_) and matches.
Một điều lưu ý là sau khi tin nhắc đầu tiên được gửi đi và đã phản hồi lại, thì lần gửi thứ hai trở đi sẽ không có bất kỳ tin phản hỏi nào nữa từ tiến trình <0.40.0>.
Đó là bởi vì hàm dolphin của chúng ta chỉ chạy , đợi một lần duy nhất, sau khi nó in ra dòng chữ "Heh, we're smarter than you humans.", hàm này sẽ kết thúc
và chấm dứt tiến trình, do đó bạn sẽ gửi tới một địa chỉ không tòn tại nữa và không có phản hồi gì cả. Và để có phản hồi lại, bạn sẽ cần phải khởi tạo lại tiến trình cho hàm dolphin.
<0.40.0>.
This is due to the fact once our function output "Heh, we're smarter than you humans.", it terminated and so did the process. We'll need to restart the dolphin:
8> f(Dolphin). ok 9> Dolphin = spawn(dolphins, dolphin1, []). <0.53.0> 10> Dolphin ! fish. So long and thanks for all the fish! fish
Đó như bạn thấy tin nhắn được gửi đi cùng vơi nội fish đã hoạt động. tuy nhiên sẽ thực sự tốt hơn khi phản hồi từ hàm dolphin là một giá trị
có thể sử dụng thay vì chỉ đơn thuần là in ra thông tin bằng hàm io:format/2. Dĩ liên là lên vậy ( Nhưng tại sao tôi lại hỏi vậy ? ).
Ngay từ phần đầu của chương này tôi đã đề cập tới việc chúng ta sẽ quan sát một tiến trình nhận một tin nhắn thế nào và cách nó phản hồi lại.
để làm điều này, chúng ta sẽ gọi định danh của một tiến trình vào bên trong một bộ theo dạng {Pid, Message}.
Hãy viết một hàm dolphin mới vầ bổ sung thêm phần logic:
And this time the fish message works. Wouldn't it be useful to be able to receive a reply from the dolphin rather than having to use io:format/2?
Of course it would (why am I even asking?) I've mentioned earlier in this chapter that the only manner to know if a process had received a message is to send a reply.
Our dolphin process will need to know who to reply to. This works like it does with the postal service. If we want someone to know answer our letter, we need to add our address.
In Erlang terms, this is done by packaging a process' pid in a tuple. The end result is a message that looks a bit like {Pid, Message}.
Let's create a new dolphin function that will accept such messages:
dolphin2() ->
receive
{From, do_a_flip} ->
From ! "How about no?";
{From, fish} ->
From ! "So long and thanks for all the fish!";
_ ->
io:format("Heh, we're smarter than you humans.~n")
end.
Nhin xem, ở hàm dolphin2 này chúng ta sẽ thay các đoạn mẫu atom như do_a_flip và fish
bằng các cặp bộ, ở đây chúng ta sẽ sử dụng From để chứ định danh của điến trình mà đã gửi tin nhắn tới.
do_a_flip and fish for messages,
we now require a variable From. That's where the process identifier will go.
11> c(dolphins).
{ok,dolphins}
12> Dolphin2 = spawn(dolphins, dolphin2, []).
<0.65.0>
13> Dolphin2 ! {self(), do_a_flip}.
{<0.32.0>,do_a_flip}
14> flush().
Shell got "How about no?"
ok
Tuyệt, dường như nó hoạt đông rất tốt. Bây giờ đã có thể nhận được một tin nhắc phản hòi từ tin nhắc mà ta đã gửi đi được rồi ( chúng ta càn thêm một địa chỉ cho mỗi một tin nhắc gửi đi ),
Nhưng khoan có vẻ như sau mỗi một tin nhắn đã được xử lí chúng ta lại phải tạo lại một tiến trình mới, điều này thật bất tiên, vậy có cách nào
mà không cần phải tạo mới tiến trình ko? Có, chúng ta có thể áp dụng đệ quy, và đây là cách mà đê quy tỏa sáng.
Để thực hiện rất đơn giản chúng ta chỉ cân gọi đệ trong hàm dolphin để tạo ra một vòng lặp vô hạn khiến cho hàm không bao giờ chấm dứt.
Dứoi đây là cách thực hiện thông qua hàm dolphin3/0:
It seems to work pretty well. We can receive replies to messages we sent (we need to add an address to each message),
but we still need to start a new process for each call. Recursion is the way to solve this problem.
We just need the function to call itself so it never ends and always expects more messages.
Here's a function dolphin3/0 that puts this in practice:
dolphin3() ->
receive
{From, do_a_flip} ->
From ! "How about no?",
dolphin3();
{From, fish} ->
From ! "So long and thanks for all the fish!";
_ ->
io:format("Heh, we're smarter than you humans.~n"),
dolphin3()
end.
Nhìn vào vd, bạn thấy tôi đã tao ra vòng lặp bằng cách đặt vào đoạn mẫu catch-all và do_a_flip một lời gọi hàm đề quy.
Một điều lưu ý là do tính chất của hàm đệ quy đuôi do đó bạn không phải lo lắng về vấn đề tràn ngăn xếp nếu sủ dụng lời gọi đệ quy.
Và như thây, các tin nhắc được gửi đi, hàm dolphin sẽ xử lí và phản hồi lại đồng thời đoạn lặp sẽ tiếp tục đợi các tin nhắc khác được gửi tới.
Nhưng, ở trong mâu fish chúng ta không thêm lời gọi đệ quy để tạo vòng lặp, dó đó nếu bạn gửi tin nhắc tới mẫu này, nó sẽ phản hồi và kết thúc hàm đó.
clause both loop with the help of dolphin3/0. Note that the function will not blow the stack because it is tail recursive.
As long as only these messages are sent, the dolphin process will loop indefinitely.
However, if we send the fish message, the process will stop:
15> Dolphin3 = spawn(dolphins, dolphin3, []).
<0.75.0>
16> Dolphin3 ! Dolphin3 ! {self(), do_a_flip}.
{<0.32.0>,do_a_flip}
17> flush().
Shell got "How about no?"
Shell got "How about no?"
ok
18> Dolphin3 ! {self(), unknown_message}.
Heh, we're smarter than you humans.
{<0.32.0>,unknown_message}
19> Dolphin3 ! Dolphin3 ! {self(), fish}.
{<0.32.0>,fish}
20> flush().
Shell got "So long and thanks for all the fish!"
ok
And that should be it for dolphins.erl.
As you see, it does respect our expected behavior of replying once for every message and keep going afterwards,
except for the fish call. The dolphin got fed up with our crazy human antics and left us for good.

There you have it. This is the core of all of Erlang's concurrency. We've seen processes and basic message passing. There are more concepts to see in order to make truly useful and reliable programs. We'll see some of them in the next chapter, and more in the chapters after that.